The last period has been full of nice conferences, which is great, but the productivity lowers :)
However I am back with a nice piece of proof that the JGrass console is a nice thing.
I would like to show you how to use the Kriging module and explain a bit of what is behind the tecnique I used.
The Kriging module is written in fortran. I wrapped its methods from C functions and compiled alltogether into a dynamic library. The functions are:
int initializepoint(double *xbasin, double *ybasin, double *zbasin, int nbasin)
{
finitializepoint_(xbasin, ybasin, zbasin, &nbasin);
return 0;
}
int initializegrid(double *window)
{
finitializegrid_(window);
return 0;
}
int getValues(double *xstation,double *ystation, double *zstation,int* nstaz,
double *rain, double *interpolatedrain) {
int ret = fgetvalues_(xstation, ystation, zstation,
nstaz, rain,
interpolatedrain);
return ret;
}
int finish()
{
int ret = ffinish_();
return ret;
}
I then used the jna library (as previously explained
here) to create the native calls from java, which results in a quick:
public interface KrigingLibrary extends Library {
KrigingLibrary INSTANCE = (KrigingLibrary) Native.loadLibrary("kriging", KrigingLibrary.class);
void initializepoint( double[] xbasin, double[] ybasin, double[] zbasin, int nbasin );
void initializegrid( double[] window );
void getValues( double[] xstation, double[] ystation, double[] zstation, int[] nstaz,
double[] rain, double[] interpolatedrain );
void finish();
}
That is all I did to access the native fortran code from java.
What is the result?
Assume that I have a region with some monitoring points and a layer of polygons. And assume that the monitoring points are rain measurement stations and are on a spatial database, geometry and timeseries. And assume also that I have a layer of polygons representing basins, inside the baricenter of which I need to calculare the rain, given through a Kriging interpolation.
Something like the below:
Alright, here is the JGrass script to do so:
String startDate = "2006-09-07 00:00";
String endDate = "2006-09-10 00:00";
jgrass {
h.kriging --iscalar-timeseries [ db.readts
--tssql "select p.id_punti_monitoraggio,t.dataora,t.valore from punti_monitoraggio p, metadati m, serie_temporali t where p.id_punti_monitoraggio similar to '(MPID)' and p.id_punti_monitoraggio=m.punti_monitoraggio_id and t.metadati_id=m.id and m.tipologia_serie_temporali_id=2 and t.intervallo = 30 and t.dataora BETWEEN cast('STARTDATE' as Timestamp) and cast('ENDDATE' as Timestamp) order by t.dataora,p.id_punti_monitoraggio"
--mpsql "select distinct p.id_punti_monitoraggio, x(shape), y(shape) from punti_monitoraggio p, metadati m where p.id_punti_monitoraggio=m.punti_monitoraggio_id and m.tipologia_serie_temporali_id=2 and x(shape) between WEST AND EAST AND y(shape) between SOUTH AND NORTH"
--start $startDate
--end $endDate
--dt 30
--bounds "5202000,5145000,1681300,1603100"
--memorymapped "false"
--oscalar-timeseries * ]
--dogrid "false"
--ishapefile-positions "/home/moovida/TMP/kriging_poly.shp"
--oscalar-outputmap dummy
}
Where --tssql defines the query to be done to the database (the connection to which is defined in the JGrass preferences) in order to get a ID,DATE,VALUE of the timeseries. STARTDATE AND ENDDATE are substituted from the parameters, as you may have guessed, as well as NORTH, SOUTH, EAST and WEST.
MPID are taken from the --mpsql query, which returns an ordered set of station infos: ID, X, Y
--dogrid "false" tells the kriging that we don't want the resulting interpolation as raster format. If "true", it would interpolate the values over a regular grid and write down a map for that.
In that case the module reads the polygon layer calulates its baricenters and then interpolates the rain properly.
I have the possibility to set also a startdate, enddate and a timestep for the model:
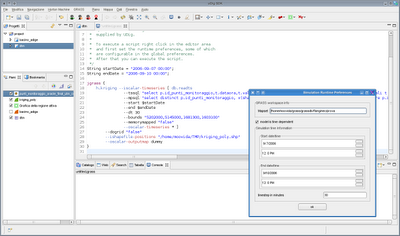
Which will trigger the reader to read those dates from the database and interpolate at the given timesteps.
In this case we had 126 basins. Just to quickly show the result, I attached an --oscalar-outputmap in order to just print the result to console:
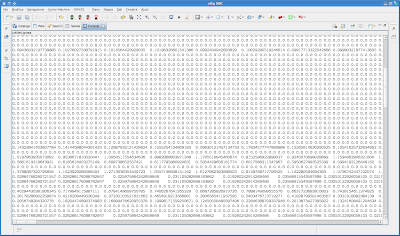
I have still a bug on the gridded Kriging part, so I can't show you the result with many maps that you would for sure like more, but I will update as soon as I solve that one.



























